
GWFish Tutorial#
This is a brief guide on how to use GWFish software
#! pip install -q git+https://github.com/janosch314/GWFish.git
#! pip install -q lalsuite
#! pip install -q corner
Settings for working locally with GWFish#
Install GWFish in a conda environment#
It is advisable to create a conda environment where to make the GWFish modules available
conda create --name gwfish_env python=3.9
conda activate gwfish_env
To make GWFish modules available from any location in your PC, after clonig the repository
git clone git@github.com:janosch314/GWFish.git
from the folder location, and after activating the conda environment, execute the command
pip install .
The following packages need to be installed as well:
pip install lalsuite
pip install corner
pip install tqdm
pip install pandas
pip install tables
pip install sympy
For numpy it is preferred to have a version below 2.0; since it is usually automatically installed with the conda environment, the suggestion is to uninstall it if the versione is \(\ge 2\) and downgrade it:
pip uninstall numpy
pip install numpy==1.25
What is the code about#
GWFish is a Fisher matrix code, useful to calculate the covariance matrix for a gravitational wave (GW) event in a really small amout of computational time (around seconds). Let’s take a step back and briefly recap how parameter estimation (PE) is done in the GW field.
Starter: GW data analysis#
Bayesian gravitational wave data analysis is used to infer the properties of gravitational wave sources and make predictions about their parameters (see below what are in detail the parameters we are talking about). It combines the principles of Bayesian statistics with the analysis of gravitational wave signals detected by ground-based observatories like LIGO and Virgo.
The goal of Bayesian gravitational wave data analysis is to extract this information from the noisy gravitational wave signals detected by the observatories:
where \(h_0(t)\) is the true (unknown) signal and \(n(t)\) is the detector noise, assumed to be Gaussian and stationary.
Mathematically, Bayes’ theorem can be expressed as:
where \(p(\vec{\theta}|d)\) is the posterior distribution, \({\mathcal{L}}(d|\vec{\theta})\) is the likelihood function, \(\pi(\vec{\theta})\) is the prior distribution, and we neglected the evidence or marginal likelihood at the denominator.
To perform Bayesian gravitational wave data analysis, we use various techniques such as Markov Chain Monte Carlo (MCMC) sampling and nested sampling. The mostly used software is bilby, and typically full Baysian parameter estimation is computationally expensive.
GW SNR Calculation and Matched Filtering#
When a gravitational-wave (GW) signal passes through a detector, the observed strain \(d(t)\) is the sum of the true signal \(h_0(t)\) and the detector noise \(n(t)\):
We assume \(n(t)\) is a zero-mean, stationary, Gaussian random process. Its properties are defined in the frequency domain by the one-sided Power Spectral Density (PSD) \(S_n(f)\):
1. The Gravitational-Wave Inner Product#
To account for the frequency-dependent sensitivity of the detector, we define a natural inner product between two functions \(a(t)\) and \(b(t)\) as:
This metric effectively “whitens” the data, giving less weight to frequency bins where the noise \(S_n(f)\) is high.
2. Matched Filtering#
The goal of matched filtering is to pull a known signal shape (template) \(h(t)\) out of the noisy data \(d(t)\). The filter output \(z\) is the projection of the data onto the template using the inner product:
If the data contains only noise (\(d = n\)), the variance of the filter output is:
3. Defining the SNR (\(\rho\))#
The Signal-to-Noise Ratio (SNR), denoted by \(\rho\), is the ratio of the filtered signal to the standard deviation of the noise:
If the template \(h\) perfectly matches the signal \(h_0\), the expected value of the SNR (the Optimal SNR) is simply the norm of the signal:
4. Optimal Filter and Maximum SNR#
According to the Cauchy–Schwarz inequality, the SNR is maximized when the filter shape matches the signal shape exactly. The optimal filter response in the frequency domain is:
Substituting this into the SNR definition gives the standard formula for the maximum achievable SNR:
5. Detection Criterion#
In practice, a trigger is considered a potential GW event if its matched-filter SNR exceeds a specific threshold:
This value is chosen to suppress the False Alarm Rate (FAR) caused by Gaussian fluctuations and non-Gaussian instrumental “glitches.”
GW parameters#
The parameters describind a GW event are the following (they are already provided with the same nomenclature as used in the code):
chirp_mass: chirp mass of the binary in [Msol] (in detector frame)
mass_ratio: ratio of the secondary mass over the primary mass, so that it ranges in \([0,1]\)redshift: the redshift of the mergerluminosity_distance: the luminosity distance of the merger in [Mpc]
theta_jn: the angle between the line of observation and the total angular momentum (orbital, spin and GR corrections) of the binary [rad] (it reduces to the so-called inclination angle or iota if the spin component is absent); it ranges in \([0, \pi]\)dec: declination angle in [rad], it varies in \([-\pi/2, +\pi/2]\)ra: right ascension in [rad], it varies in \([0, 2/pi]\)psi: the polarization angle in [rad]; it ranges in \([0, \pi]\)
For an L-shaped detector:
psi = 0 → + and × aligned with the detector arms
psi = π/4 → rotated by 45°, i.e. equal mix of + and ×
phase: the initial phase of the merger in [rad]; it ranges in \([0, 2\pi]\)geocent_time: merger time as GPS time in [s]; it starts from 1980a_1: dimensionless spin parameter of primary component; it ranges in \([0, 1]\)a_2: dimensionless spin parameter of secondary component; it ranges in \([0, 1]\)tilt_1: zenith angle between the spin and orbital angular momenta for the primary component in [rad]; it ranges in \([0, \pi]\)tilt_2: zenith angle between the spin and orbital angular momenta for the secondary component in [rad]; it ranges in \([0, \pi]\)phi_12: difference between total and orbital angular momentum azimuthal angles in [rad]; it ranges in \([0, 2\pi]\)phi_jl: difference between the azimuthal angles of the individual spin vector projections on to the orbital plane in [rad]; it ranges in \([0, 2\pi]\)lambda_1: dimensionless tidal polarizabilty of primary componentlambda_2: dimensionless tidal polarizabilty of secondary component
The lambda_1 and lambda_2 parameters are for neutron stars only and their value spans from a few hundreds to a thousand.

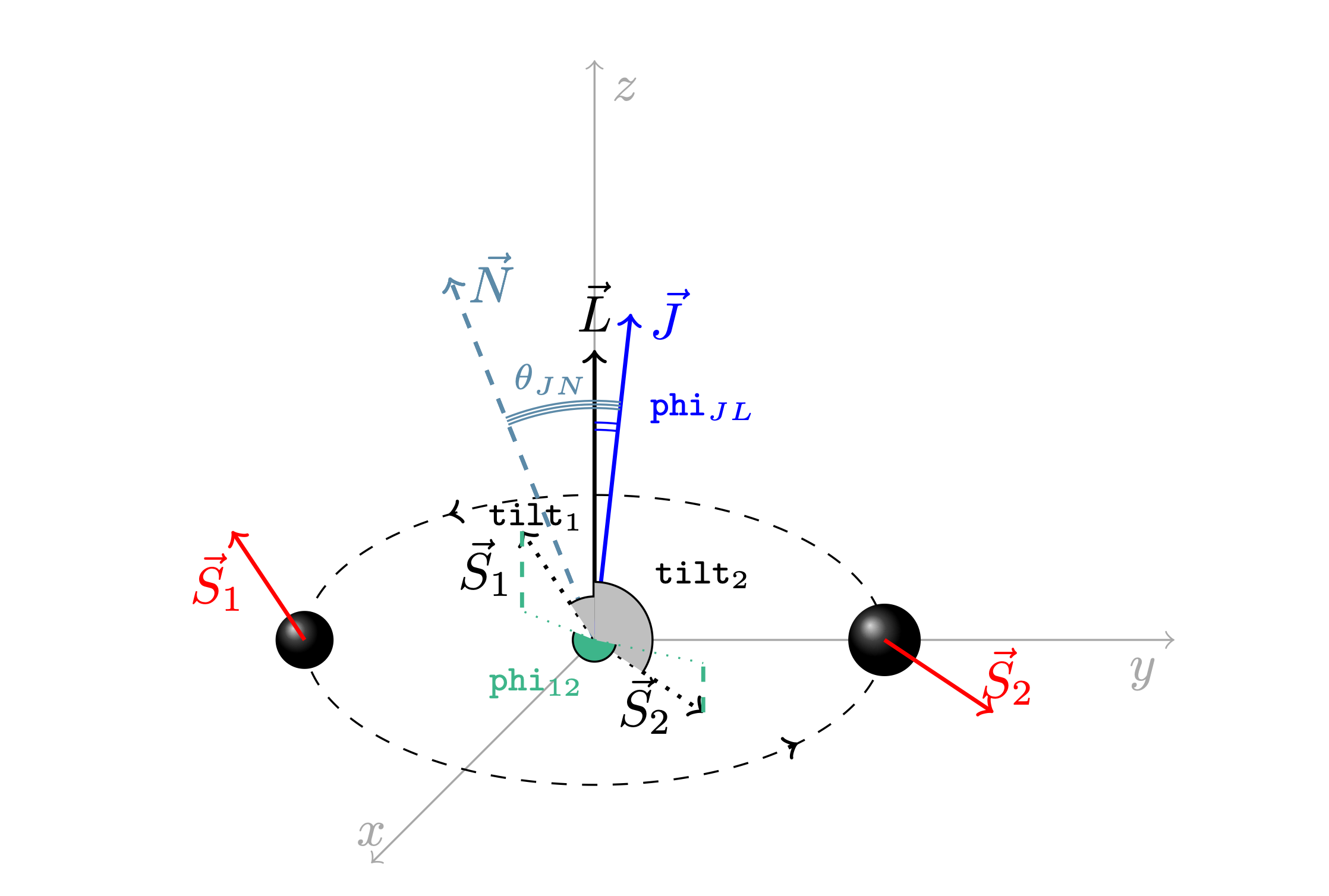
Look at https://arxiv.org/pdf/2404.16103 to see an exhaustive descriptions of parameters
Note on mass conventions#
In GWFish the input masses can be passed in the following different combinations (the combination has to be the same when selecting the fisher_params):
chirp_mass(in detector-frame and in [Msol]) andmass_ratiochirp_mass_source(in source-frame and in [Msol]) andmass_ratiomass_1andmass_2, both in detector-frame and in [Msol]mass_1_sourceandmass_2_source, both in source-frame and in [Msol]
Pay attention that when masses are passed to lal they are always converted into mass_1 and mass_2 (in [kg]), as lal always takes masses in detector frame!
Why Fisher analysis?#
When studying the performance of a new detector, such as the Einstein Telescope, which has a much improved sensitivity and is predicted to detect entire populations of events (\(10^6\) events per years against the current tens that we are detecting), we want a tool to make forecasts in a reasonable amoiunt of time. Since we do not have still a fast full parameter estimation, the Fisher matrix approximation is the state-of-the-art for forecasts.
Let’s start!#
The implementation of a Fisher matrix code relies on three main pillars:
Analytic waveform approximation:
GWFishuses all the waveforms fromlalsimulationin frequency domain (although it is also possble to work in time domain)Derivatives: these are done numerically at the second order (except for some parameters, like distance, phase and time, which are straightforward analytically)
Matrix inversion: singular value decomposition and normalization is used to safely invert the Fisher matrix
Import packages#
# suppress warning outputs for using lal in jupuyter notebook
import warnings
warnings.filterwarnings("ignore", "Wswiglal-redir-stdio")
import GWFish.modules as gw
from tqdm import tqdm
import matplotlib
import matplotlib.pyplot as plt
import corner
import numpy as np
import pandas as pd
import json
import os
from astropy.cosmology import Planck18
# plotting settings
matplotlib.rcParams.update({
'font.size': 10,
'axes.labelsize': 10,
'axes.titlesize': 10,
'xtick.labelsize': 10,
'ytick.labelsize': 10,
'legend.fontsize': 10,
'figure.titlesize': 10
})
Single Event Analysis: GW170817-like#
# Event's parameters should be passed as Pandas dataframe
parameters = {
'chirp_mass': np.array([1.1858999987203738]) * (1 + 0.00980),
'mass_ratio': np.array([0.8308538032620448]),
'luminosity_distance': Planck18.luminosity_distance(0.00980).value,
'theta_jn': np.array([2.545065595974997]),
'ra': np.array([3.4461599999999994]),
'dec': np.array([-0.4080839999999999]),
'psi': np.array([0.]),
'phase': np.array([0.]),
'geocent_time': np.array([1187008882.4]),
'a_1':np.array([0.005136138323169717]),
'a_2':np.array([0.003235146993487445]),
'lambda_1':np.array([368.17802383555687]),
'lambda_2':np.array([586.5487031450857])}
parameters = pd.DataFrame(parameters)
parameters
| chirp_mass | mass_ratio | luminosity_distance | theta_jn | ra | dec | psi | phase | geocent_time | a_1 | a_2 | lambda_1 | lambda_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.197522 | 0.830854 | 43.747554 | 2.545066 | 3.44616 | -0.408084 | 0.0 | 0.0 | 1.187009e+09 | 0.005136 | 0.003235 | 368.178024 | 586.548703 |
# We choose a waveform approximant suitable for BNS analysis
# In this case we are taking into account tidal polarizability effects
waveform_model = 'IMRPhenomD_NRTidalv2'
f_ref = 10.
⚠️ Note:#
The default reference frequency
f_refis set to \(50\), the user can pass a different value, together with thewaveform_modelparameter (see examples below)
Play with the signal#
# To access the available detectors, use the following command
gw.utilities.get_available_detectors()
dict_keys(['ET', 'VOY', 'CE1', 'CE2', 'LLO', 'LHO', 'VIR', 'VIR_O2', 'KAG', 'LIN', 'LISA', 'LGWA', 'LGWA_Nb', 'LGWA_Soundcheck'])
A quick note on detectors setup#
Detectors are all described in the .yaml file. The general settings are as follows (in case you want to customize your own detector):
ET: # name label of the detector
lat: (40 + 31. / 60 ) * np.pi / 180.
lon: (9 + 25. / 60) * np.pi / 180.
opening_angle: np.pi / 3.
azimuth: 70.5674 * np.pi / 180. #angle between the main arm and the north, clockwise
psd_data: ET_psd.txt # file containg two columns: frequency, psd
duty_factor: 0.85
detector_class: earthDelta # for triangle-shaped detector or earthL if usual-shape detector
plotrange: 3, 1000, 1e-25, 1e-20
fmin: 2. # minimum frequency of the detector
fmax: 2048. # maximum frequency of the detector
spacing: geometric
df: 1./16.
npoints: 1000
arm_length: 10000
The spacing variable can either be geometric (logarithmic spacing of the frequency vector for waveform evaluation with a number of points specified by the npoints variable, faster solution) or linear (linear spacing of the frequency vector to evaluate the waveform with spacing given by df, slower solution)
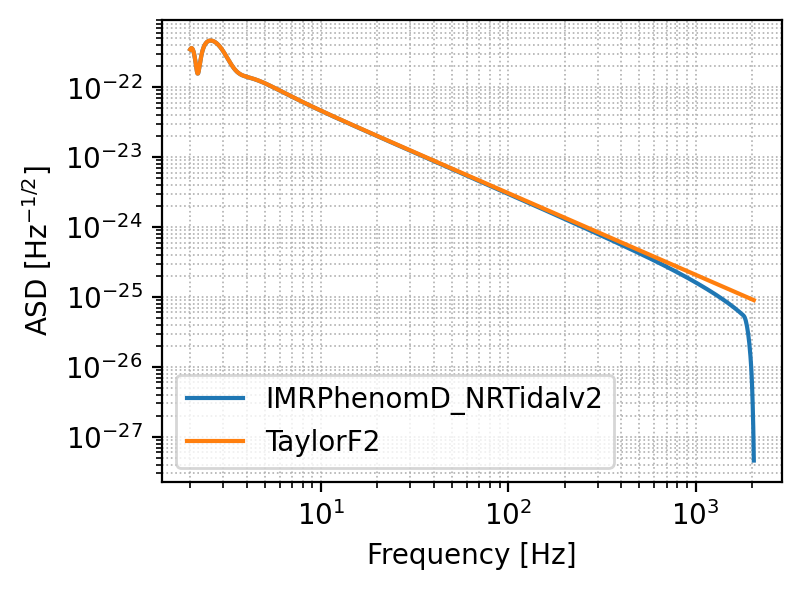
Plot the signal#
Let’s start getting a feeling of how the signal appears
# Choose the detector onto which you want to project the signal
detector = 'ET'
plt.figure(figsize=(4, 3), dpi=200)
# The following function outputs the signal projected onto the chosen detector
waveform_model_1 = 'IMRPhenomD_NRTidalv2'
signal_1, _ = gw.utilities.get_fd_signal(parameters, detector, waveform_model_1, f_ref) # waveform_model and f_ref are passed together
waveform_model_2 = 'TaylorF2'
signal_2, _ = gw.utilities.get_fd_signal(parameters, detector, waveform_model_2, f_ref) # waveform_model and f_ref are passed together
frequency = gw.detection.Detector(detector).frequencyvector[:, 0]
# This signal has three components since ET comprises three detectors, let's plot one of them
plt.loglog(frequency, np.abs(signal_1[:, 0]), label='%s' %waveform_model_1)
plt.loglog(frequency, np.abs(signal_2[:, 0]), label='%s' %waveform_model_2)
plt.legend()
plt.xlabel('Frequency [Hz]')
plt.ylabel('ASD [Hz$^{-1/2}$]')
plt.grid(linestyle='dotted', linewidth='0.6', which='both')
plt.show()
Gravitational Wave Waveform Approximants Overview#
This guide provides a comprehensive overview of waveform approximants available in LALSimulation for gravitational wave analysis.
Reference: LALSimulation Documentation
Basic Difference: IMRPhenom vs SEOBNR#
IMRPhenom (IMRP)
Phenomenological waveform fitted to numerical relativity (NR) + post-Newtonian (PN) results
Mainly frequency-domain
Fast to compute, covers inspiral-merger-ringdown (IMR)
Good for typical spins/mass ratios, less accurate in extreme cases
SEOBNR (SEOB)
Effective-One-Body (EOB) waveform based on analytical GR, calibrated to NR
Mainly time-domain
More accurate for high spins, precession, eccentricity, and higher modes
Slower to compute than IMRPhenom
Summary Table:
Feature |
IMRPhenom (IMRP) |
SEOBNR (SEOB) |
|---|---|---|
Basis |
Phenomenological fit |
Analytical EOB + NR calibration |
Domain |
Frequency-domain |
Time-domain |
Speed |
Fast |
Slower |
Accuracy |
Good for common cases |
High, especially for extreme cases |
Use |
Quick parameter estimation |
High-accuracy studies / GR tests |
Time Domain Waveforms#
TaylorT1: PN time-domain waveform, 1st order in timeTaylorT2: PN time-domain waveform, 2nd order in timeTaylorT3: PN time-domain waveform, 3rd order in timeTaylorT4: PN time-domain waveform, 4th order in timeSEOBNRv4: Effective-one-body waveform with aligned spins (v4)SEOBNRv5: Effective-one-body waveform with aligned spins (v5)
Frequency Domain Waveforms#
TaylorF2: PN frequency-domain waveform (most commonly used PN)IMRPhenomA: Phenomenological IMR waveform (non-spinning)IMRPhenomB: Phenomenological IMR waveform (aligned spins)IMRPhenomD: Phenomenological IMR waveform (aligned spins, BBH)IMRPhenomD_NRTidalv2: IMRPhenomD + tidal effects for BNS
Binary Neutron Star (BNS) Specific#
IMRPhenomD_NRTidalv2: Includes tidal deformabilityIMRPhenomPv2_NRTidal: Tides + precessionSEOBNRv4_ROM_NRTidalv2: EOB reduced order model with tides
Higher Modes & Precession#
Precession necessary when the spins are large and mis-aligned wrt the orbital angular momentum. Higher Modes (beyond the quadrupole approximation) necessary for large mass ratios and large total mass.
IMRPhenomHM: Higher multipole moments (l=2,3,4)IMRPhenomXHM: Next-gen higher modesIMRPhenomXPHM: Precessing + higher modesSEOBNRv4PHM: EOB with precession and higher modes
NSBH (Neutron Star–Black Hole) Systems#
Typical properties: Large mass ratio, often misaligned spins, and tidal effects from the neutron star.
Recommended waveforms:
IMRPhenomNSBH— frequency-domain model including spin precession and tidal effects.IMRPhenomPv2_NRTidal— precessing waveform with tidal deformability (good general-purpose choice, but not is the BH-NS mass ratio is very large ).SEOBNRv4_ROM_NRTidalv2— EOB model with tides, accurate but slower.
When to include:
Precession: If BH spin is tilted.
Higher modes: For large mass ratios (≥ 1:5) or edge-on systems.
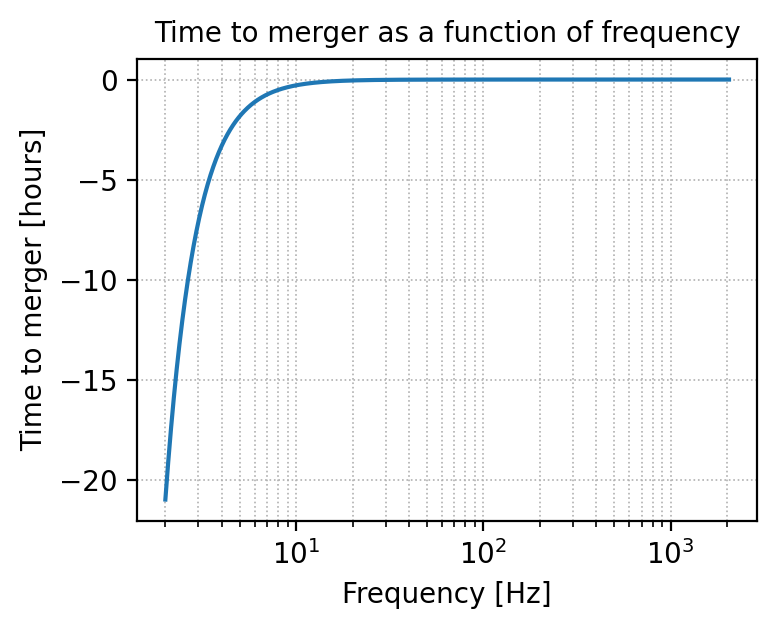
Time as a function of frequency#
# Plot the time before the merger as a function of the frequency
_, t_of_f = gw.utilities.get_fd_signal(parameters, detector, waveform_model, f_ref)
detector
'ET'
plt.figure(figsize=(4, 3), dpi=200)
convert_from_seconds_to_hours = 3600
plt.semilogx(frequency, (t_of_f - parameters['geocent_time'].iloc[0]) / convert_from_seconds_to_hours)
plt.xlabel('Frequency [Hz]')
plt.ylabel('Time to merger [hours]')
plt.grid(linestyle='dotted', linewidth='0.6', which='both')
plt.title('Time to merger as a function of frequency')
plt.show()
Calculate SNR#
# The networks are the combinations of detectors that will be used for the analysis
# The detection_SNR is the minimum SNR for a detection:
# --> The first entry specifies the minimum SNR for a detection in a single detector
# --> The second entry specifies the minimum network SNR for a detection
detectors = ['ET', 'CE1', 'LLO', 'LHO', 'VIR']
network = gw.detection.Network(detector_ids = detectors, detection_SNR = (0., 8.))
snr_1 = gw.utilities.get_snr(parameters, network, 'IMRPhenomPv2_NRTidal', f_ref)
snr_2 = gw.utilities.get_snr(parameters, network, 'TaylorF2', f_ref)
snr_1
| ET | CE1 | LLO | LHO | VIR | network | |
|---|---|---|---|---|---|---|
| event_0 | 645.185225 | 1126.175241 | 85.506804 | 101.145441 | 27.430804 | 1304.924868 |
snr_2
| ET | CE1 | LLO | LHO | VIR | network | |
|---|---|---|---|---|---|---|
| event_0 | 654.652687 | 1139.647308 | 87.783936 | 103.842227 | 28.060927 | 1321.606133 |
snr_1['network']/snr_2['network']
event_0 0.987378
Name: network, dtype: float64
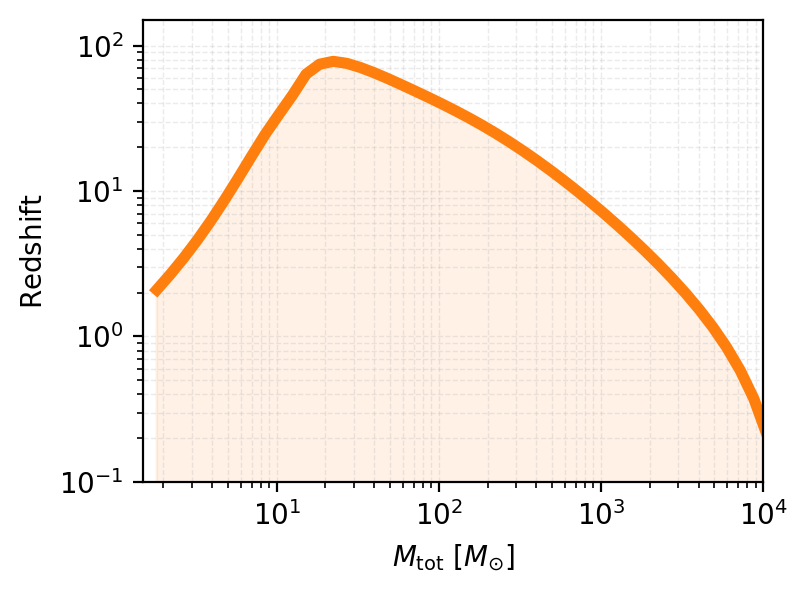
Horizon Distance vs. Range: Key Differences#
In gravitational wave astronomy, horizon distance and range are two related but distinct concepts used to characterize detector sensitivity:
Horizon Distance#
The horizon distance is the maximum luminosity distance at which a gravitational wave detector can observe a source with a signal-to-noise ratio (SNR) equal to a specified detection threshold (typically SNR = 8).
Key characteristics:
Assumes an optimally oriented and located binary system (face-on, overhead)
Represents the best-case scenario for detection
Provides an upper limit on detector reach
Range#
The range is the distance at which a detector can observe sources with random orientations and sky locations, averaged over all possible angles, at the detection threshold SNR.
Key characteristics:
Accounts for the angular dependence of GW signal strength
Represents a more realistic detection capability
Typically smaller than the horizon distance by a factor of ~2-3
Relation to horizon:
for a uniformly distributed population in orientation and sky position.
# example event
masses = np.logspace(-0.1, 4, 50)
hor_params = {
'mass_ratio':1.,
'theta_jn':0.,
'psi': 0.,
'phase': 0.,
'geocent_time': 0.
}
network = gw.detection.Network(['ET'])
redshifts_snr = []
for mass in tqdm(masses):
hor_params['chirp_mass_source'] = mass
opt_parameters = gw.horizon.find_optimal_location(hor_params, network, waveform_model='IMRPhenomD')
distance, redshift_det = gw.horizon.horizon(opt_parameters, network, target_SNR=8, waveform_model='IMRPhenomD')
redshifts_snr.append(redshift_det)
100%|██████████| 50/50 [00:39<00:00, 1.26it/s]
# convert from chirp mass and mass ratio to total mass
def chirp_mass_q_to_total_mass(chirp_mass, mass_ratio):
return chirp_mass * (1 + mass_ratio) ** (6/5) / (mass_ratio ** (3/5))
plt.figure(figsize=(4, 3), dpi=200)
# plot the results: mass vs redshift
plt.loglog(chirp_mass_q_to_total_mass(masses, np.ones_like(masses)), redshifts_snr, color='tab:orange', linewidth=4, alpha=1)
# color the space below the curve
plt.fill_between(chirp_mass_q_to_total_mass(masses, np.ones_like(masses)), 0, redshifts_snr, color='tab:orange', alpha=0.1)
plt.xlabel(r'$M_{\rm tot}$ $[M_{\odot}]$')
plt.ylabel(r'$\rm Redshift$')
plt.grid(True, which="both", linestyle="--", linewidth=0.5, alpha=0.25)
plt.ylim(0.1, 150)
plt.xlim(1.5, 10000)
plt.show()
Parameter estimation#
Bayesian gravitational wave data analysis is used to infer the properties of gravitational wave sources and make predictions about their parameters (see below what are in detail the parameters we are talking about). It combines the principles of Bayesian statistics with the analysis of gravitational wave signals detected by ground-based observatories like LIGO and Virgo.
The goal of Bayesian gravitational wave data analysis is to extract this information from the noisy gravitational wave signals detected by the observatories:
where \(h_0(t)\) is the true (unknown) signal and \(n(t)\) is the detector noise, assumed to be Gaussian and stationary.
Mathematically, Bayes’ theorem can be expressed as:
where \(p(\vec{\theta}|s)\) is the posterior distribution, \(\mathscr{L}(s|\vec{\theta})\) is the likelihood function, \(\pi(\vec{\theta})\) is the prior distribution, and we neglected the evidence or marginal likelihood at the denominator.
To perform Bayesian gravitational wave data analysis, we use various techniques such as Markov Chain Monte Carlo (MCMC) sampling and nested sampling. The mostly used software is bilby, and typically full Baysian parameter estimation is computationally expensive.
Fisher-matrix approximation#
The gravitational-wave likelihood is defined as the probability of noise realization:
The inner product \(\langle \cdot|\cdot\rangle\) measures the overlap between two signals given the noise characteristics of the detector:
We can approximate the likelihood by expanding the template around the true signal:
so that the likelihood becomes a multivariarte Gaussian distribution:
The truncation in the expansion is done at first-order in partial derivatives, known as linearized signal approximation (LSA)
LSA approximation is equivalent to the leading term in posterior expansion as a series in 1/SNR (this is the reason why Fisher matrix is said to work in high-SNR limit) [see Vallisneri 2008]
The dominant term is the one with the Fisher likelihood:
The inverse of the Fisher matrix gives us the covariance matrix among parameters:
This is the basic math behind Fisher matrix codes, like GWFish.
Calculate \(1\sigma\) Errors#
For a more realistic analysis we can include the duty cycle of the detectors using use_duty_cycle = True
# The fisher parameters are the parameters that will be used to calculate the Fisher matrix
# and on which we will calculate the errors
fisher_parameters = ['chirp_mass', 'mass_ratio', 'luminosity_distance', 'theta_jn', 'dec','ra',
'psi', 'phase', 'geocent_time', 'a_1', 'a_2', 'lambda_1', 'lambda_2']
detected, network_snr, parameter_errors, sky_localization = gw.fishermatrix.compute_network_errors(
network = gw.detection.Network(detector_ids = ['ET'], detection_SNR = (0., 8.)),
parameter_values = parameters,
fisher_parameters=fisher_parameters,
waveform_model = waveform_model,
f_ref = 20.,
)
# use_duty_cycle = False, # default is False anyway
# save_matrices = False, # default is False anyway, put True if you want Fisher and covariance matrices in the output
# save_matrices_path = None, # default is None anyway,
# otherwise specify the folder
# where to save the Fisher and
# corresponding covariance matrices
100%|██████████| 1/1 [00:00<00:00, 3.10it/s]
print('The network SNR of the event is ', network_snr)
The network SNR of the event is [645.00540645]
print('The sky localization of the event is ', sky_localization)
The sky localization of the event is [4.75415021e-05]
# Choose percentile factor of sky localization and pass from rad2 to deg2
percentile = 90.
sky_localization_90cl = sky_localization * gw.fishermatrix.sky_localization_percentile_factor(percentile)
sky_localization_90cl # in deg2!!
array([0.71872681])
# One can create a dictionary with the parameter errors, the order is the same as the one given in fisher_parameters
parameter_errors_dict = {}
for i, parameter in enumerate(fisher_parameters):
parameter_errors_dict['err_' + parameter] = np.squeeze(parameter_errors)[i]
print('The parameter errors of the event are ')
parameter_errors_dict
The parameter errors of the event are
{'err_chirp_mass': 7.72772062478848e-07,
'err_mass_ratio': 0.012457691886787943,
'err_luminosity_distance': 2.251713928473747,
'err_theta_jn': 0.07997827997775477,
'err_dec': 0.0036304744266439223,
'err_ra': 0.004552362939462272,
'err_psi': 0.12334740159080766,
'err_phase': 0.24840265150763793,
'err_geocent_time': 9.92535556871366e-05,
'err_a_1': 0.1748839167388211,
'err_a_2': 0.21749201995398468,
'err_lambda_1': 2555.01137110076,
'err_lambda_2': 4606.837234927146}
Save results to file#
There is another function analyze_and_save_to_txt that allows to save the results to a file. The difference with respect to the compute_network_errors function is that one can pass different network combinations and get results files for each of them. This means that if your detectors list is something like ['LHO', 'LLO', 'VIR', 'CE1', 'ET'] and you want to create 3 different networks out of it, i.e. ['LHO', 'LLO', 'VIR'], ['CE1', 'ET'] and ['ET'] alone, then one should inizialize the analyze_and_save_to_txt function as follows:
network = gw.detection.Network(detector_ids = ['LHO', 'LLO', 'VIR', 'CE1', 'ET'], detection_SNR = (0., 8.))
and then specify the different network combinations:
sub_network_ids_list = [[0, 1, 2], [3, 4], [4]]
# create forlder where store results
!mkdir tutorial_results
mkdir: tutorial_results: File exists
data_folder = 'tutorial_results' # the one we just created
network = gw.detection.Network(detector_ids = ['ET'], detection_SNR = (0., 8.))
gw.fishermatrix.analyze_and_save_to_txt(network = network,
parameter_values = parameters,
fisher_parameters = fisher_parameters,
sub_network_ids_list = [[0]],
population_name = 'BNS',
waveform_model = waveform_model,
f_ref = 20.,
save_path = data_folder,
save_matrices = True)
100%|██████████| 1/1 [00:00<00:00, 3.31it/s]
fisher_matrix = np.load(data_folder + '/' + 'fisher_matrices_ET_BNS_SNR8.npy')
errors = pd.read_csv(data_folder + '/' + 'Errors_ET_BNS_SNR8.txt', delimiter = ' ')
# One can access all the column names of the errors output file:
errors.keys()
Index(['network_SNR', 'chirp_mass', 'mass_ratio', 'luminosity_distance',
'theta_jn', 'ra', 'dec', 'psi', 'phase', 'geocent_time', 'a_1', 'a_2',
'lambda_1', 'lambda_2', 'err_chirp_mass', 'err_mass_ratio',
'err_luminosity_distance', 'err_theta_jn', 'err_dec', 'err_ra',
'err_psi', 'err_phase', 'err_geocent_time', 'err_a_1', 'err_a_2',
'err_lambda_1', 'err_lambda_2', 'err_sky_location'],
dtype='object')
Same errors as before just save to a .txt file:
errors
| network_SNR | chirp_mass | mass_ratio | luminosity_distance | theta_jn | ra | dec | psi | phase | geocent_time | ... | err_dec | err_ra | err_psi | err_phase | err_geocent_time | err_a_1 | err_a_2 | err_lambda_1 | err_lambda_2 | err_sky_location | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 645.005406 | 1.198 | 0.8309 | 43.75 | 2.545 | 3.446 | -0.4081 | 0.0 | 0.0 | 1.187000e+09 | ... | 0.00363 | 0.004552 | 0.1233 | 0.2484 | 0.000099 | 0.1749 | 0.2175 | 2555.0 | 4607.0 | 0.000048 |
1 rows × 28 columns
A quick test#
One would expect that the Fisher matrix entry corresponding to dL-dL should be approximated by the ratio between the SNR and the luminosity distance squared as follows:
where \(\Delta d_L = \sqrt{\left[F\right]^{-1}_{d_L,d_L}}\), with \(F\) the Fisher matrix.
This can be derived from the fact that \(\partial_{d_L}h = -\frac{1}{d_L}h\). Indeed
where \(\tilde{h}_0(f)\) is the intrinsic waveform amplitude independent of distance. Taking the derivative with respect to luminosity distance:
Therefore:
where the inverse of the error on distance is the corresponding entry of the Fisher matrix \(F_{d_L,d_L}\) (assuming correlations are negligible).
A rough approximation in literature takes: \(\frac{\Delta d_L}{d_L} \sim \frac{2}{SNR}\).
my_fisher = fisher_matrix[0, :, :]
print('We expect Delta dL/dL to scale as 1/SNR')
print('fisher matrix dL-dL: ', my_fisher[2, 2])
print('(SNR/dL)^2: ', (errors['network_SNR'].iloc[0] / errors['luminosity_distance'].iloc[0])**2)
We expect Delta dL/dL to scale as 1/SNR
fisher matrix dL-dL: 217.37978198571082
(SNR/dL)^2: 217.35548047427832
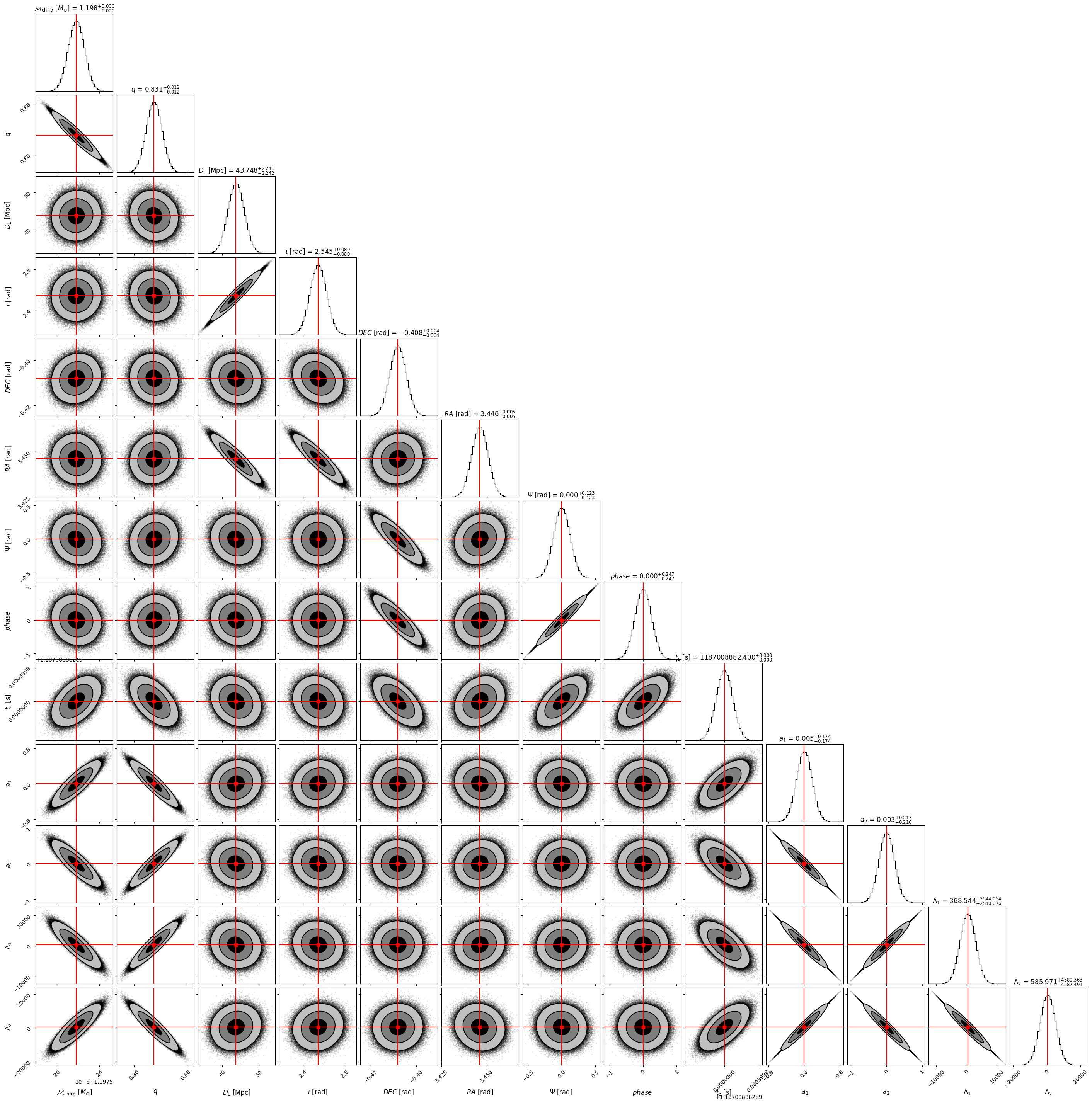
Corner plot#
The covariance matrix can be used to show all the correlations between pairs of parameters in a corner plot. Using as inputs the injected values and the covariance matrix, one samples from a multivariate Gaussian distribution and plot the samples.
CORNER_KWARGS = dict(
bins = 50, # number of bins for histograms
smooth = 0.99, # smooths out contours.
plot_datapoints = True, # choose if you want datapoints
label_kwargs = dict(fontsize = 12), # font size for labels
show_titles = True, #choose if you want titles on top of densities.
title_kwargs = dict(fontsize = 12), # font size for title
plot_density = False,
title_quantiles = [0.16, 0.5, 0.84], # add quantiles to plot densities for 1d hist
levels = (1 - np.exp(-0.5), 1 - np.exp(-2), 1 - np.exp(-9 / 2.)), # 1, 2 and 3 sigma contours for 2d plots
fill_contours = True, #decide if you want to fill the contours
max_n_ticks = 2, # set a limit to ticks in the x-y axes.
title_fmt=".3f"
)
corner_lbs = [r'${\mathcal{M}}_{\rm chirp}$ $[M_{\odot}]$', r'$q$', r'$D_{\rm L}$ [Mpc]',
r'$\iota$ [rad]', r'$DEC$ [rad]', r'$RA$ [rad]', r'$\Psi$ [rad]',
r'$phase$', r'$t_c$ [s]', r'$a_1$', r'$a_2$', r'$\Lambda_1$', r'$\Lambda_2$']
mean_lbs = ['chirp_mass', 'mass_ratio', 'luminosity_distance', 'theta_jn', 'dec', 'ra', 'psi',
'phase', 'geocent_time', 'a_1', 'a_2', 'lambda_1', 'lambda_2']
mean_values = parameters[mean_lbs].iloc[0] # mean values of the parameters
cov_matrix = np.load(data_folder + '/' + 'inv_fisher_matrices_ET_BNS_SNR8.npy')[0, :, :]
# Sample from a multi-variate gaussian with the given covariance matrix and injected mean values
samples = np.random.multivariate_normal(mean_values, cov_matrix, int(1e6))
fig = corner.corner(samples, labels = corner_lbs, truths = mean_values, truth_color = 'red',
**CORNER_KWARGS)
plt.show()
/var/folders/sy/4t6z4zzj41n_hpwrc85v_4hm0000gn/T/ipykernel_90627/2349962579.py:2: RuntimeWarning: covariance is not symmetric positive-semidefinite.
samples = np.random.multivariate_normal(mean_values, cov_matrix, int(1e6))
/opt/anaconda3/envs/acme_env/lib/python3.10/site-packages/corner/core.py:846: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
if xs[k1] is not None:
/opt/anaconda3/envs/acme_env/lib/python3.10/site-packages/corner/core.py:847: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
axes[k1, k1].axvline(xs[k1], **kwargs)
/opt/anaconda3/envs/acme_env/lib/python3.10/site-packages/corner/core.py:849: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
if xs[k1] is not None:
/opt/anaconda3/envs/acme_env/lib/python3.10/site-packages/corner/core.py:850: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
axes[k2, k1].axvline(xs[k1], **kwargs)
/opt/anaconda3/envs/acme_env/lib/python3.10/site-packages/corner/core.py:851: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
if xs[k2] is not None:
/opt/anaconda3/envs/acme_env/lib/python3.10/site-packages/corner/core.py:852: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
axes[k2, k1].axhline(xs[k2], **kwargs)
Validity of the Fisher matrix approach#
Check appendix section of https://arxiv.org/pdf/2205.02499
Population Analysis#
The functions are the same explained in the previous tutorial, but applied to a population sample instead of a single event
# Example for BNS population
nev = 50 # number of events
my_dict = {}
my_dict['redshift'] = np.random.uniform(0.01, 0.1, nev)
my_dict['mass_1'] = np.random.uniform(1.1, 2.5, nev)
my_dict['mass_2'] = np.random.uniform(1.1, 2.5, nev)
my_dict['luminosity_distance'] = Planck18.luminosity_distance(my_dict['redshift']).value
my_dict['theta_jn'] = np.arccos(np.random.uniform(-1., 1., nev))
my_dict['ra'] = np.random.uniform(0., 2 * np.pi, nev)
my_dict['dec'] = np.arcsin(np.random.uniform(-1., 1., nev))
my_dict['psi'] = np.random.uniform(0., np.pi, nev)
my_dict['phase'] = np.random.uniform(0., 2 * np.pi, nev)
my_dict['geocent_time'] = np.random.uniform(1577491218, 1609027217, nev)
my_dict['a_1'] = np.random.uniform(0., 0.1, nev)
my_dict['a_2'] = np.random.uniform(0., 0.1, nev)
aux_mass = my_dict['mass_1'] # sort the two masses so that m1>m2
my_dict['mass_1'] = np.maximum(aux_mass, my_dict['mass_2'])
my_dict['mass_2'] = np.minimum(aux_mass, my_dict['mass_2'])
my_pop = pd.DataFrame(my_dict)
my_pop.head(5)
| redshift | mass_1 | mass_2 | luminosity_distance | theta_jn | ra | dec | psi | phase | geocent_time | a_1 | a_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.013939 | 1.933814 | 1.503675 | 62.418798 | 1.754590 | 3.628387 | 0.541124 | 0.375881 | 5.817387 | 1.602320e+09 | 0.098589 | 0.085373 |
| 1 | 0.093333 | 2.306439 | 1.307017 | 442.135135 | 2.187549 | 1.230691 | -0.303948 | 1.886734 | 2.133756 | 1.594383e+09 | 0.017712 | 0.049855 |
| 2 | 0.035627 | 2.082790 | 1.737968 | 162.114788 | 1.354276 | 0.227025 | -0.233185 | 2.123156 | 5.832686 | 1.584348e+09 | 0.025370 | 0.033085 |
| 3 | 0.067025 | 1.536121 | 1.458447 | 311.866513 | 1.013232 | 2.600142 | 1.006577 | 2.481659 | 3.746476 | 1.598545e+09 | 0.008727 | 0.004200 |
| 4 | 0.080970 | 2.339112 | 1.695586 | 380.383437 | 1.541504 | 1.068148 | 0.277534 | 0.757756 | 1.869701 | 1.606690e+09 | 0.063566 | 0.066721 |
detectors_pop = ['ET']
network_pop = gw.detection.Network(detector_ids = detectors_pop, detection_SNR = (0., 8.))
waveform_model_pop = 'IMRPhenomHM'
fisher_parameters_pop = ['mass_1', 'mass_2', 'luminosity_distance', 'theta_jn', 'dec','ra',
'psi', 'phase', 'geocent_time', 'a_1', 'a_2']
!mkdir pop_gwfish_results
mkdir: pop_gwfish_results: File exists
data_folder_pop = 'pop_gwfish_results'
gw.fishermatrix.analyze_and_save_to_txt(network = network_pop,
parameter_values = my_pop,
fisher_parameters = fisher_parameters_pop,
sub_network_ids_list = [[0]],
population_name = 'BNS_POP',
waveform_model = waveform_model_pop, # if no f_ref is passed, the code will use the default value of 50 Hz
save_path = data_folder_pop,
save_matrices = False)
100%|██████████| 50/50 [00:16<00:00, 2.95it/s]
pop_errors = pd.read_csv(data_folder_pop + '/' + 'Errors_ET_BNS_POP_SNR8.txt', delimiter = ' ')
pop_errors.head(5)
| network_SNR | redshift | mass_1 | mass_2 | luminosity_distance | theta_jn | ra | dec | psi | phase | ... | err_luminosity_distance | err_theta_jn | err_dec | err_ra | err_psi | err_phase | err_geocent_time | err_a_1 | err_a_2 | err_sky_location | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 458.845361 | 0.01394 | 1.934 | 1.504 | 62.42 | 1.755 | 3.628 | 0.5411 | 0.3759 | 5.817 | ... | 1.408 | 0.001859 | 0.02299 | 0.05005 | 0.03216 | 0.009009 | 0.000489 | 0.06384 | 0.08523 | 0.003074 |
| 1 | 52.991279 | 0.09333 | 2.306 | 1.307 | 442.10 | 2.188 | 1.231 | -0.3039 | 1.8870 | 2.134 | ... | 102.400 | 0.238800 | 0.05481 | 0.04307 | 0.28400 | 0.605200 | 0.001067 | 0.25630 | 0.49070 | 0.007075 |
| 2 | 109.243523 | 0.03563 | 2.083 | 1.738 | 162.10 | 1.354 | 0.227 | -0.2332 | 2.1230 | 5.833 | ... | 7.390 | 0.029360 | 0.02185 | 0.04617 | 0.03431 | 0.057440 | 0.000786 | 0.29630 | 0.36420 | 0.002885 |
| 3 | 98.568932 | 0.06703 | 1.536 | 1.458 | 311.90 | 1.013 | 2.600 | 1.0070 | 2.4820 | 3.746 | ... | 31.960 | 0.064820 | 0.09120 | 0.14630 | 0.21460 | 0.125900 | 0.001182 | 0.54820 | 0.58410 | 0.020960 |
| 4 | 85.399171 | 0.08097 | 2.339 | 1.696 | 380.40 | 1.542 | 1.068 | 0.2775 | 0.7578 | 1.870 | ... | 31.790 | 0.005865 | 0.18550 | 0.24530 | 0.11840 | 0.052980 | 0.001584 | 0.27410 | 0.39470 | 0.132500 |
5 rows × 25 columns
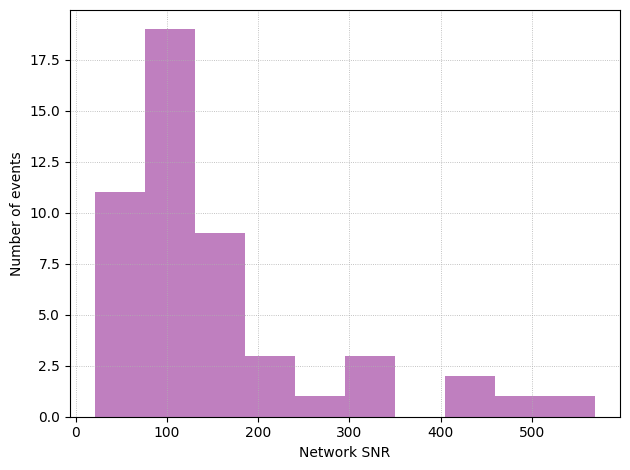
plt.hist(pop_errors['network_SNR'], bins = 10, color = 'purple', alpha = 0.5, linewidth = 2)
plt.xlabel('Network SNR')
plt.ylabel('Number of events')
plt.grid(linestyle='dotted', linewidth='0.6', which='both')
plt.tight_layout()
plt.show()
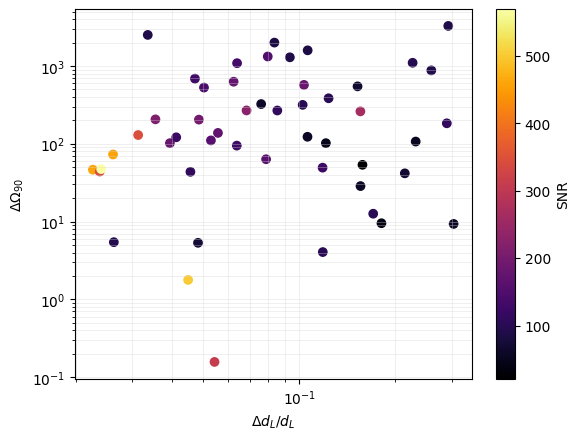
percentile_pop = 90
sky_loc_90cl_pop = pop_errors['err_sky_location'] * gw.fishermatrix.sky_localization_percentile_factor(percentile_pop)
sc = plt.scatter(pop_errors['err_luminosity_distance'] / pop_errors['luminosity_distance'],
sky_loc_90cl_pop, c = pop_errors['network_SNR'], cmap = 'inferno')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('$\Delta d_L/d_L$')
plt.ylabel('$\Delta \Omega_{%s}$' %int(percentile))
plt.colorbar(sc, label = 'SNR')
plt.grid(which = 'both', color = 'lightgray', alpha = 0.5, linewidth = 0.5)
plt.show()
GWFish meets Priors#
In Bayesian analysis, we start with prior beliefs about the parameters of the model, which represent our initial knowledge or assumptions. These priors can be informed by astrophysical models, previous observations, or theoretical predictions. As we observe a gravitational wave signal, we update these beliefs using the likelihood function, which quantifies the probability of observing the data given the parameters. The result is the posterior distribution, which represents our updated knowledge about the parameters after considering the data.
One of the advantages of the Bayesian approach is its ability to incorporate prior information and quantify uncertainties in a rigorous way. By combining prior knowledge with the observed data, we can make more informed inferences about the properties of the gravitational wave source.
The Fisher matrix analysis works in the assumption that when the signal to noise ratio (SNR) is sufficiently large, the likelihood is a highly peaked function and no priors are needed. However, this is rarely the case, as correlations may spread the likelihood and sampling from the multivariate Gaussian may leak outside the physical range of parameters.
In this tutorial, we show how to integrate prior information, \(\pi(\vec{\theta})\), into the Fisher likelihood while maintaining computational efficiency in the sampling process. Additionally, we offer insights into the comparative behavior of different prior choices.
The procedure is addressed in a second GWFish paper available on arXiv. The usage of the code as for the paper’s purposes can be found in this repo.
Introducing the new modules#
This part is based on the new module priors.py and the sampling procedure relies on the minimax_tilting_sampler.py module (see below). It consists in building on top of the standard GWFishoutput and incorporate prior information in post-processing.
import warnings
warnings.filterwarnings("ignore", "Wswiglal-redir-stdio")
import GWFish.modules as gw
from GWFish.modules.priors import *
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
# Event's parameters should be passed as Pandas dataframe
parameters = {
'chirp_mass': np.array([20]),
'mass_ratio': np.array([0.75]),
'luminosity_distance': np.array([500.]),
'theta_jn': np.array([0.06*np.pi]),
'ra': np.array([np.pi/4]),
'dec': np.array([np.pi/4]),
'psi': np.array([np.pi/4]),
'phase': np.array([np.pi/4]),
'geocent_time': np.array([1187008882]),
'a_1':np.array([0.2]),
'a_2':np.array([0.2]),
'tilt_1':np.array([np.pi/4]),
'tilt_2':np.array([np.pi/4]),
'phi_12':np.array([np.pi/4]),
'phi_jl':np.array([np.pi/4])}
parameters = pd.DataFrame(parameters)
parameters
| chirp_mass | mass_ratio | luminosity_distance | theta_jn | ra | dec | psi | phase | geocent_time | a_1 | a_2 | tilt_1 | tilt_2 | phi_12 | phi_jl | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20 | 0.75 | 500.0 | 0.188496 | 0.785398 | 0.785398 | 0.785398 | 0.785398 | 1187008882 | 0.2 | 0.2 | 0.785398 | 0.785398 | 0.785398 | 0.785398 |
# The fisher parameters are the parameters that will be used to calculate the Fisher matrix
# and on which we will calculate the errors
fisher_parameters = list(parameters.keys())
detected, network_snr, parameter_errors, sky_localization = gw.fishermatrix.compute_network_errors(
network = gw.detection.Network(detector_ids = ['LLO'], detection_SNR = (0., 8.)),
parameter_values = parameters,
fisher_parameters=fisher_parameters,
waveform_model = 'IMRPhenomXPHM',
save_matrices = True # you need to save the covariance matrix for the next steps
)
100%|██████████| 1/1 [00:01<00:00, 1.43s/it]
Post-processing with priors#
np.random.seed(42) # fix for reproducibility
rng = np.random.default_rng()
# Decide the number of samples to draw
num_samples = int(1e6)
param_lbs = {'chirp_mass': r'$\mathcal{M}_c$ $[M_{\odot}]$', 'mass_ratio': r'$q$', 'luminosity_distance': r'$d_L$ [Mpc]',
'dec': r'$\texttt{DEC}$ [rad]', 'ra': r'$\texttt{RA}$ [rad]', 'theta_jn': r'$\theta_{JN}$ [rad]', 'psi': r'$\Psi$ [rad]',
'phase': r'$\phi$ [rad]', 'geocent_time': r'$t_c$ [rad][s]', 'a_1': r'$a_1$', 'a_2': r'$a_2$',
'tilt_1': r'$\theta_1$ [rad]', 'tilt_2': r'$\theta_2$ [rad]', 'phi_12': r'$\phi_{12}$ [rad]',
'phi_jl': r'$\phi_{JL}$ [rad]'}
mean_values = np.array(parameters[fisher_parameters ].iloc[0]) # mean values of the parameters
cov_matrix = np.load('inv_fisher_matrices.npy')[0, :, :]
fisher_samples = pd.DataFrame(rng.multivariate_normal(mean_values, cov_matrix, int(1e6)), columns = fisher_parameters)
/var/folders/sy/4t6z4zzj41n_hpwrc85v_4hm0000gn/T/ipykernel_90627/341241274.py:14: RuntimeWarning: covariance is not symmetric positive-semidefinite.
fisher_samples = pd.DataFrame(rng.multivariate_normal(mean_values, cov_matrix, int(1e6)), columns = fisher_parameters)
# Calculate and print the eigenvalues of the covariance matrix
eigenvalues = np.linalg.eigvals(cov_matrix)
print("Eigenvalues of the covariance matrix:")
print(eigenvalues)
Eigenvalues of the covariance matrix:
[ 3.58380157e+04 1.96983955e+01 5.18814843e+00 1.84197175e+00
7.47926969e-01 2.24173241e-01 1.84966754e-02 4.04390188e-03
1.52665604e-03 1.15612301e-04 3.21511017e-06 9.29855798e-07
3.70096283e-08 2.72211042e-20 -4.72698808e-16]
cov_matrix = cov_matrix + 1e-3*np.eye(len(parameters))
# In priors.py the function get_truncated_likelihood_samples takes the following arguments:
# - fisher_parameters: list of parameters
# - mean_values: mean values of the parameters
# - cov_matrix: covariance matrix
# - num_samples: number of samples to draw
# - min_array: minimum values of the parameters
# - max_array: maximum values of the parameters
# The function returns the samples from the truncated likelihood
# You can get this information using the command shown in the cell above
# If min_array and max_array are not provided, the function will use the default range for each parameter
# specified in the default prior dictionary (these ranges are used to truncate the likelihood)
samples_from_truncated_lkh = get_truncated_likelihood_samples(fisher_parameters, mean_values, cov_matrix, num_samples)#, min_array, max_array)
Warning: Method may fail as covariance matrix is close to singular!
# Plot the posterior distribution of the parameter of choice
sel_param = 'luminosity_distance'
injections = np.array(mean_values)
fig = plt.figure(figsize=(6, 4))
plt.hist(fisher_samples[sel_param], bins=50, histtype='step', density=False,
label='Fisher', alpha = 1., color = 'black')
plt.hist(samples_from_truncated_lkh[sel_param], bins=50, histtype='step', density=False,
label='Fisher + Truncated', alpha = 1., color = 'blue')
#plt.hist(samples_from_posterior[sel_param], bins=50, histtype='step', density=True,
# label='Fisher + Truncated + Priors', alpha = 1., color = 'red')
plt.axvline(injections[fisher_parameters.index(sel_param)], color='black', linestyle='--', label='True Value')
plt.xlabel(param_lbs[sel_param])
plt.ylabel('PDF')
fig.legend(loc='center', bbox_to_anchor=(0.5, 0.95), ncol=2, frameon=False)
plt.show()
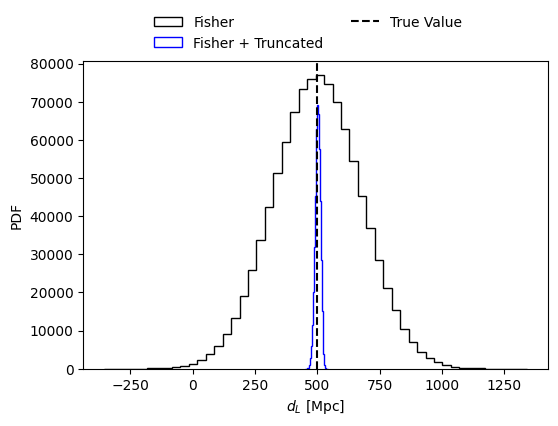
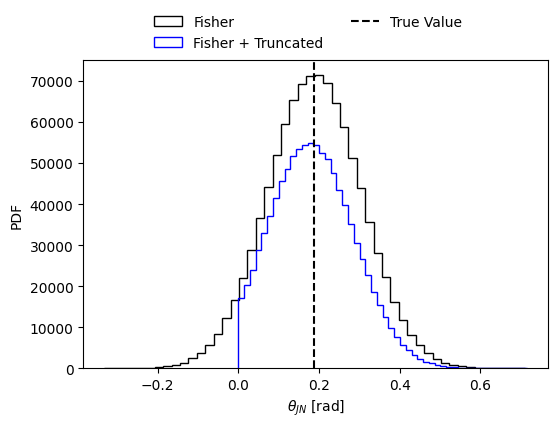
# Plot the posterior distribution of the parameter of choice
sel_param = 'theta_jn'
injections = np.array(mean_values)
fig = plt.figure(figsize=(6, 4))
plt.hist(fisher_samples[sel_param], bins=50, histtype='step', density=False,
label='Fisher', alpha = 1., color = 'black')
plt.hist(samples_from_truncated_lkh[sel_param], bins=50, histtype='step', density=False,
label='Fisher + Truncated', alpha = 1., color = 'blue')
#plt.hist(samples_from_posterior[sel_param], bins=50, histtype='step', density=True,
# label='Fisher + Truncated + Priors', alpha = 1., color = 'red')
plt.axvline(injections[fisher_parameters.index(sel_param)], color='black', linestyle='--', label='True Value')
plt.xlabel(param_lbs[sel_param])
plt.ylabel('PDF')
fig.legend(loc='center', bbox_to_anchor=(0.5, 0.95), ncol=2, frameon=False)
plt.show()
Priors dictionary example#
priors_dict = {}
priors_dict['chirp_mass'] = {
'prior_type': 'uniform_in_component_masses_chirp_mass',
'lower_prior_bound': parameters['chirp_mass'].iloc[0] - 5.,
'upper_prior_bound': parameters['chirp_mass'].iloc[0] + 5.
}
priors_dict['mass_ratio'] = {
'prior_type': 'uniform_in_component_masses_mass_ratio',
'lower_prior_bound': 0.05,
'upper_prior_bound': 0.99
}
priors_dict['luminosity_distance'] = {
'prior_type': 'uniform_in_distance_squared',
'lower_prior_bound': 0,
'upper_prior_bound': 2300
}
priors_dict['theta_jn'] = {
'prior_type': 'uniform_in_cosine',
'lower_prior_bound': 0,
'upper_prior_bound': np.pi/12
}
priors_dict['ra'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': 2*np.pi
}
priors_dict['dec'] = {
'prior_type': 'uniform_in_cosine',
'lower_prior_bound': -np.pi/2,
'upper_prior_bound': np.pi/2
}
priors_dict['psi'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': np.pi
}
priors_dict['phase'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': 2*np.pi
}
priors_dict['geocent_time'] = {
'prior_type': 'uniform',
'lower_prior_bound': parameters['geocent_time'].iloc[0] - 3,
'upper_prior_bound': parameters['geocent_time'].iloc[0] + 3
}
priors_dict['a_1'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': 1.
}
priors_dict['a_2'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': 1.
}
priors_dict['tilt_1'] = {
'prior_type': 'uniform_in_sine',
'lower_prior_bound': 0.,
'upper_prior_bound': np.pi
}
priors_dict['tilt_2'] = {
'prior_type': 'uniform_in_sine',
'lower_prior_bound': 0.,
'upper_prior_bound': np.pi
}
priors_dict['phi_12'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': 2*np.pi
}
priors_dict['phi_jl'] = {
'prior_type': 'uniform',
'lower_prior_bound': 0.,
'upper_prior_bound': 2*np.pi
}
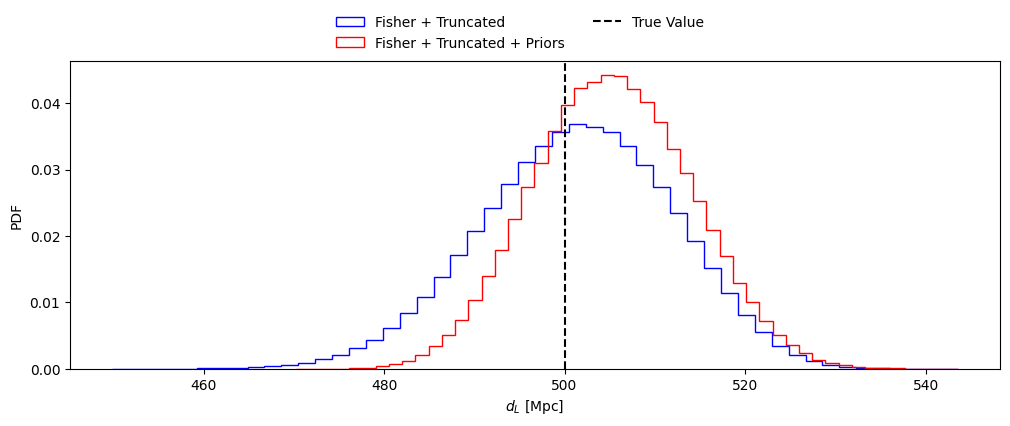
# To avoid having a large number of samples outside the physical range, we apply the prior to the samples from
# the truncated likelihood. The function get_posteriors_samples takes the following arguments:
# - fisher_parameters: list of parameters
# - samples_from_truncated_lkh: samples from the truncated likelihood
# - num_samples: number of samples to draw
# - priors_dict: dictionary with the prior ranges for each parameter (if not provided, the default prior dictionary is used)
samples_from_posterior = get_posteriors_samples(fisher_parameters, samples_from_truncated_lkh, num_samples, priors_dict=priors_dict)#, priors_dict)
# Plot the posterior distribution of the parameter of choice
sel_param = 'luminosity_distance'
injections = np.array(mean_values)
fig = plt.figure(figsize=(12, 4))
#plt.hist(fisher_samples[sel_param], bins=50, histtype='step', density=True,
# label='Fisher', alpha = 1., color = 'black')
plt.hist(samples_from_truncated_lkh[sel_param], bins=50, histtype='step', density=True,
label='Fisher + Truncated', alpha = 1., color = 'blue')
plt.hist(samples_from_posterior[sel_param], bins=50, histtype='step', density=True,
label='Fisher + Truncated + Priors', alpha = 1., color = 'red')
plt.axvline(injections[fisher_parameters.index(sel_param)], color='black', linestyle='--', label='True Value')
plt.xlabel(param_lbs[sel_param])
plt.ylabel('PDF')
fig.legend(loc='center', bbox_to_anchor=(0.5, 0.95), ncol=2, frameon=False)
plt.show()
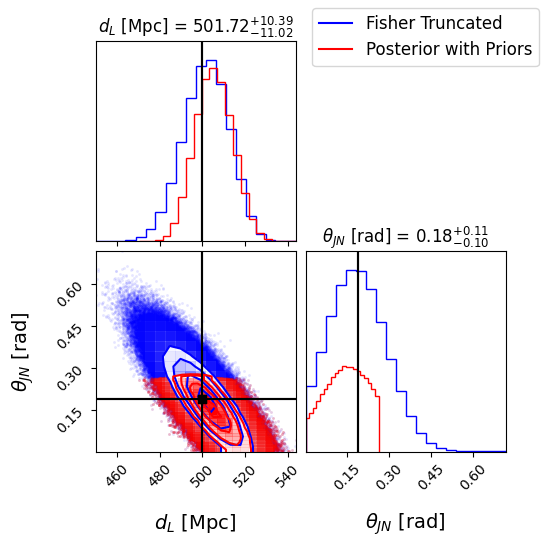
# Plot the posterior distribution of the parameter of choice using corner
plt.figure(dpi=180)
sel_params = ['luminosity_distance', 'theta_jn'] # Parameters to plot
# Extract the indices of the selected parameters
sel_indices = [fisher_parameters.index(param) for param in sel_params]
mean_lbs = ['chirp_mass', 'mass_ratio', 'luminosity_distance', 'theta_jn', 'dec', 'ra', 'psi',
'phase', 'geocent_time', 'a_1', 'a_2']
mean_values = parameters[mean_lbs].iloc[0] # mean values of the parameters
injections = np.array(mean_values)
# Extract the corresponding samples
samples_fisher_truncated = np.column_stack([samples_from_truncated_lkh[param] for param in sel_params])
samples_fisher_truncated_priors = np.column_stack([samples_from_posterior[param] for param in sel_params])
# Extract the true values for the selected parameters
true_values = injections[sel_indices]
# Create the corner plot
fig = corner.corner(samples_fisher_truncated, labels=[param_lbs[param] for param in sel_params],
truths=true_values, truth_color='black', color='blue', alpha=0.5,
label_kwargs={'fontsize': 14}, show_titles=True, title_kwargs={"fontsize": 12}, dpi = 180)
corner.corner(samples_fisher_truncated_priors, labels=[param_lbs[param] for param in sel_params],
truths=true_values, truth_color='black', color='red', alpha=0.5, fig=fig)
# Add legend
handles = [plt.Line2D([], [], color='blue', label='Fisher Truncated'),
plt.Line2D([], [], color='red', label='Posterior with Priors')]
fig.legend(handles=handles, loc='upper right', fontsize=12)
plt.show()
<Figure size 1152x864 with 0 Axes>
Parameter estimation for pre-merger#
#parameter estimation fot pre-merger
modify this line janosch314/GWFish
pre_merger_time = 60. polarizations[ np.where(self.t_of_f > (self.gw_params[‘geocent_time’] - pre_merger_time)), :] = 0.j
This approach has been used in https://www.aanda.org/articles/aa/pdf/2023/10/aa45850-23.pdf
Exercises for the tutorial: try yourself#
Check how parameter estimation improves if you fix any of the GW parameters. Fix everything apart distance, inclination and sky position
Compare the sky localization for a 1.4 + 1.4 M_sun BNS @ 200 Mpc, face on, with LVKI and ET
repeat the exercise of adding priors assuming we have a precise measurment of the redshift (e.g. 1% in accuracy)